
Салют кибер воины! Сегодня мы хотели бы поделиться информацией о том, как можно изменить свой голос в реальном времени на компьютере. Мы заранее хотим предупредить, что чтобы достичь желаемого качества голоса, потребуется длительное обучение нейросети с использованием различных голосовых записей. Этот процесс потребует сбора десятков гигабайт аудиофайлов и несколько сотен часов времени.

Как изменить свой голос с помощью нейросети
Следуйте точно приведенной ниже инструкции и старайтесь выполнять все последовательно:
- Заходим на GitHub по ссылке:
github.com/vlomme/Multi-Tacotron-Voice-Cloningи скачиваем архив;
- Скачиваем готовый адсет для будущего голоса по ссылке:
openslr.org/resources/12/train-clean-100.tar.gz; - Если вы когда-нибудь устанавливали “Avatarify” (подмена лица), то у вас должна быть установленная “Anaconda prompt “, ссылка:
anaconda.com/download#downloads. В случае, если этого не было — скачиваем версию под “Python 3.7”; - Скачиваем и устанавливаем тулкит “CUDA 10.0”, ссылка:
developer.nvidia.com/cuda-10.0-download-archive; - После всех загрузок запускаем “Anaconda prompt (miniconda3)” и прописываем в консоли код:
conda create -n clone python=3.6;
- В изменившемся окне пишем “y” и нажимаем “Enter”;
- Далее необходимо активировать виртуальную среду, которую мы только что создали — для этого прописываем:
conda activate clone. После устанавливаем необходимые пакеты в консоли “Анаконды”:conda install pytorchи подтверждаем действия;
- Распаковываем архив с “Github”, который мы скачали в 1-м пункте и копируем его путь. В консоли “Анаконды” пишем команду:
cd ваш путь к файлам с архива;
- Далее пишем:
pip install -r requirements.txt;
- Как только закончится установка необходимых модулей, прописываем еще одну команду:
conda install numba; - Сейчас мы извлекаем содержимое дополнительного архива с названием “pretrained.zip”, который ранее был загружен. Это необходимо сделать в каталоге, где находится программа “Real-TimeVoice-Cloning-master”. Если вы скачали второй архив, переходим к следующему шагу: создаем подкаталог с именем “LibriSpeech” внутри каталога программы, затем в этом подкаталоге создаем каталог “train-clean-100” и копируем туда файлы из распакованного архива. Так же, что бы не было ошибок, закидываем в папку утилиты dll файлы “CUDA” —
cudart64_100.dll и cudnn64_7.dll, их можно найти в папке “C:\ProgramData\Miniconda3\pkgs\pytorch-1.0.0-py3.7_cuda100_cudnn7_1\Lib\site-packages\torch\lib“. Если вы устанавливали “Avatarify”, то тут: “ProgramData\Miniconda3\envs\avatarify\Lib\site-packages\torch\lib[/SIZE][/SIZE][/SIZE]“; - Пробуем запустить нашу чудо машину, для этого прописываем в “Анаконде” команду:
python demo_toolbox.py. Потребуется много оперативной памяти; - Видим главное меню. Сверху нажимаем “Browse” и загружаем нужный нам образец голоса в формате “.wav”, либо записываем фрагмент своего голоса с помощью кнопки “Record”. Речь должна быть четкой, старайтесь проговорить 3 предложения минимум, нейронка заточена под английский язык;
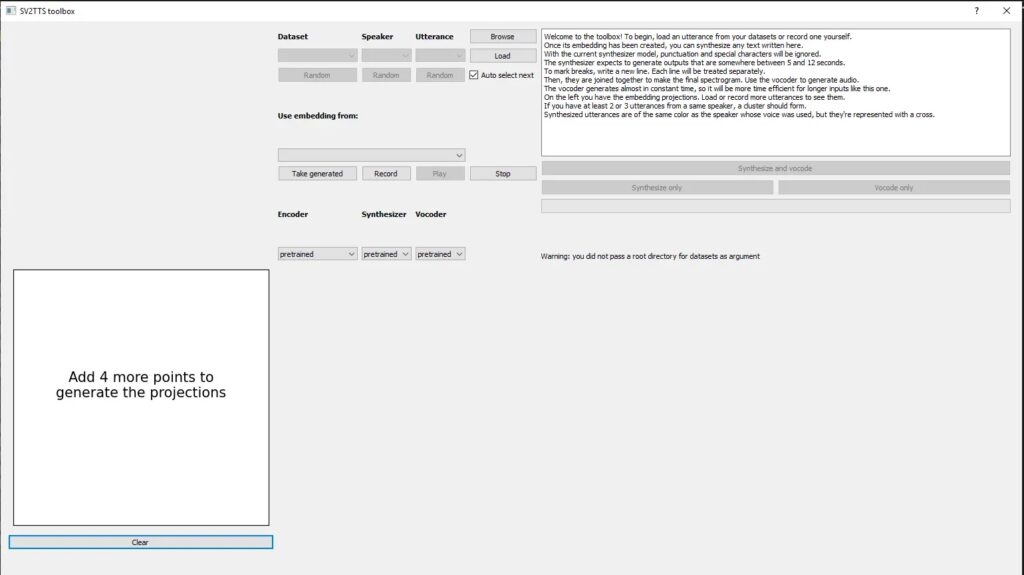
- После загрузки голоса, вводим требуемый текст на английском вверху справа, нажимаем кнопку “Synthesize and vocode”. Далее услышим полученный вариант голоса. Повторное выполнение этого алгоритма несколько раз приведет к автоматическому улучшению качества голоса.
- Сохраняем полученный результат — редактируем файл “demo_cli.py”, прописываем нужный текст и имя исходного файла. Сохраняем и в “Анаконде” и прописываем “python demo_cli.py” вместо “python demo_toolbox.py”, после чего начнется процесс генерации. По окончании процесса мы получим готовый вариант в том же каталоге;
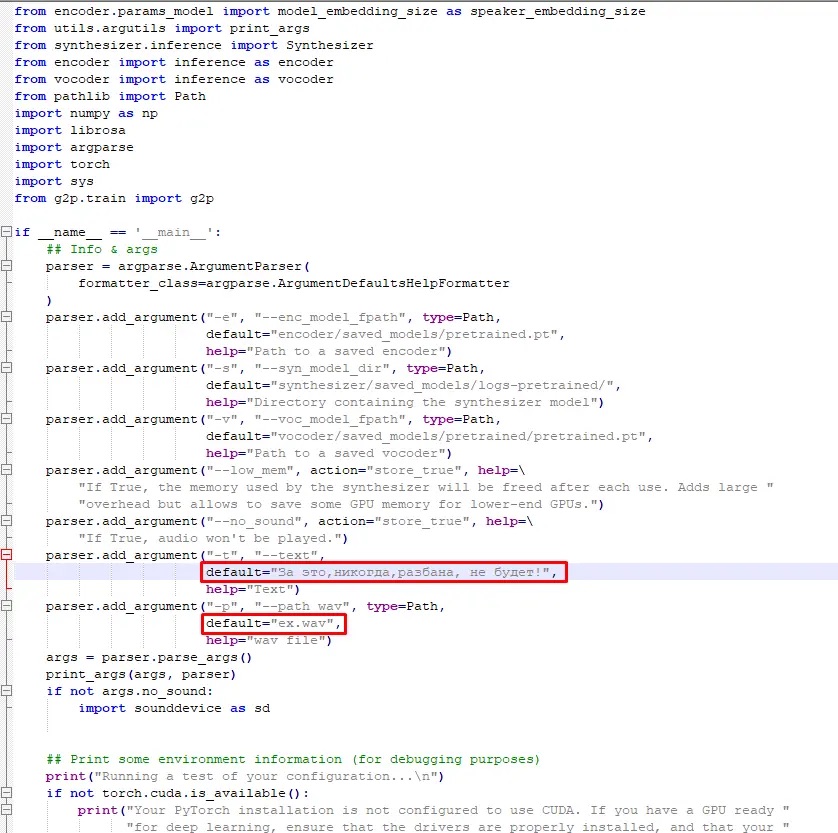
Все готово! Киберпанк уже приближается, вливаемся своевременно и пользуемся полученными знаниями с умом и во благо обществу.


На этапе установки пакетов дополнительных для Анаконды консоль выдает ошибку
DEBUG:urllib3.connectionpool:https://repo anaconda.com:443 “GET /pkgs/main/win-64/repodata.json HTTP/1.1” 304 0
failed